



Photo by Radek Grzybowski on Unsplash
Paper notes: Kafka, a Distributed Messaging System for Log Processing


For the first post in the paper notes series, I will go through a paper published in 2011 about the Kafka distributed messaging system. In a bit more than 10 years, Kafka has become the de-facto infrastructure for any log processing or event-driven system. Since 2011, the Kafka project has grown significantly but the basic concept presented in the paper stayed the same.
Problem statement
In any sizable company, log data volume is usually orders of magnitude bigger compared to "real" data (for ex., customer info or orders). Earlier systems are mostly built for offline consumption (Hadoop, ...). However,
At LinkedIn, we found that in addition to traditional offline analytics, we needed to support most of the real-time applications mentioned above with delays of no more than a few seconds.
Traditional messaging systems (ex. IBM Websphere MQ or JMS) are not well suited for log processing:
Rich set of delivery guarantees which tends to be overkill for log processing. Lead to complex API and implementation.
Throughput is not the primary constraint (ex. no batching API).
Weak distributed system support. No partitioning of data.
Expect direct consumption of messages. Degraded performance if the queue size is growing.
Large companies (like Yahoo or Facebook) also built their log aggregator by periodically dumping files in Hadoop. This approach is good for offline access but won't work for real-time data processing. The push model is also harder to work with as you need the consumers to scale linearly with the producers.
High-level concept
A stream of messages of a particular type is defined by a topic. A producer can publish messages to a topic. The published messages are then stored at a set of servers called brokers. A consumer can subscribe to one or more topics from the brokers, and consume the subscribed messages by pulling data from the brokers.
The Kafka API reflects the simplicity of the messaging concepts:
// Sample producer
producer = new Producer(...);
message = new Message(“test message str”.getBytes());
set = new MessageSet(message);
producer.send(“topic1”, set);
// Sample consumer
streams[] = Consumer.createMessageStreams(“topic1”, 1)
for (message : streams[0]) {
bytes = message.payload();
// do something with the bytes
}
A message is defined to contain an array of bytes. Kafka makes no assumption about the serialization method. On the consumer side, the message stream never terminates. If no message can be pulled, the stream will block.
Architecture
Kafka usually contains multiple brokers. To balance the load, a topic is split into multiple partitions.
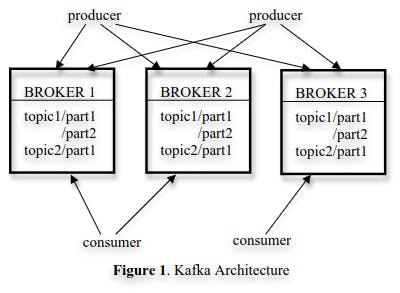
Each partition represents a logical log of messages. Kafka represents a partition as a set of segment files. A segment file is size-bounded. A new message is always appended to the latest segment.
Kafka uses several optimizations to make sure partitions are performant.
Writes are cached in memory and flushed in one go to avoid small writes.
Segment offset is used as a message identifier. The lack of message ids avoids having to keep an index to map the message id to the location on disk of the message.
Each broker keeps the first offset of each segment in memory. When a specific offset is requested, the broker knows where to read.
Producers can batch messages in a single request. Consumers eagerly fetch messages at every pull request.
No caching of messages in the broker process. Kafka relies on the filesystem page-level caching. No cold cache if the broker process restarts. Reduced overhead due to garbage collection (Kafka is written in Java).
Use sendfile system call to send bytes from disk to a socket. Avoid the overhead of two memory copies and one system call compared to a typical read/write.
The brokers don't store information about the state of their consumers to reduce complexity and overhead. Only the consumer itself knows its current offset in the partition. As an added benefit, the consumer can re-consume the partition at any time if there is a bug or a crash.
Distributed coordination
Producers can send their messages to a random partition or a specific partition given a partitioning key.
For consumers, Kafka has the concept of consumer groups. Each message is delivered only to a single consumer in the group. Multiple consumer groups can subscribe to the same topic.
To reduce the overhead as much as possible, Kafka reduces the coordination needed.
A partition is the smallest unit of parallelism in Kafka. A partition will only be consumed by a single consumer in the consumer group. Coordination is only required when there is a change in the consumer group (consumer added or removed).
No master node. Consumers coordinate among themselves using a consensus mechanism (implement here by Zookeeper). Increase availability compared to a single master node.
Delivery guarantees
Kafka guarantees at-least-once delivery. Most of the time, messages are delivered exactly once to a consumer group, except in case of failures. When a crash of a consumer happens, the latest offsets of the consumer might not have been recorded properly in Zookeeper.
The ordering of messages received by a consumer is guaranteed only in one partition. There is no cross-partition or cross-topic delivery ordering guarantees.
A CRC is stored for each message to avoid network and on-disk corruptions. There is no replication available so if a broker goes down, the messages are unavailable (this is no longer the case).
Usage at LinkedIn
Currently, Kafka accumulates hundreds of gigabytes of data and close to a billion messages per day, which we expect will grow significantly as we finish converting legacy systems to take advantage of Kafka.
LinkedIn separates its Kafka deployments into two clusters: one for real-time services and one for offline/data analysis services. The offline deployment is also used for ad-hoc querying using simple scripts against the raw events.
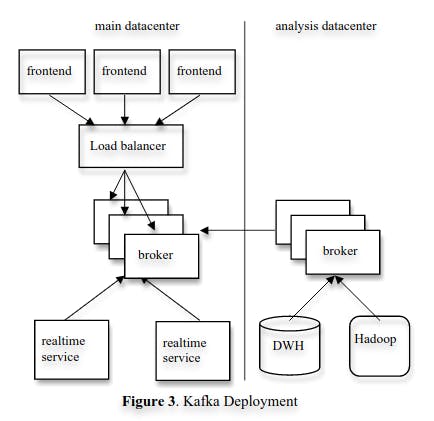
Loading data in Hadoop is implemented using a Map-Reduce mechanism reading directly data from Kafka. The data and the offsets are only stored in Hadoop upon successful completion of the job. If an error or a crash occurs, the job restarts from the start.
Conclusion
Since the paper has been written, Kafka has grown tremendously. A company, Confluent, has been created to support the development of Kafka. In terms of usage, according to the Kafka website, over 80% of Fortune 100 companies are using Kafka.
Multiple improvements to the core of the product have taken place since the system has been introduced: support of replication, transactional consumers, and the removal of Zookeeper, ... Higher-level products on top of the technology have been developed like Streams, ksqlDB, ...
I think we can safely say Kafka has had a big impact on the industry and will probably continue to do so for the foreseeable future.